


Desde hace meses CTIC Centro Tecnológico investiga nuevos métodos para la generación de datos de entrenamiento para sus algoritmos de Inteligencia Artificial. En concreto, desde la línea de especialización de Tecnologías de Visión de CTIC, en la que se estudian y desarrollan las tecnologías de Visión Artificial, Realidad Aumentada y Realidad Virtual, se trabaja en la aplicación de este enfoque a la generación de imágenes y entornos de entrenamiento, para la creación y validación de algoritmos inteligentes, que permitan reconocer de manera automática el contenido de una imagen.

Imagen 1 – Ejemplo de escenario de pruebas para control de stock en un almacén
Una de las técnicas más usadas en las últimas décadas para el desarrollo de algoritmos de visión artificial, y de cualquier otra disciplina dentro del ámbito de la inteligencia artificial, es el aprendizaje automático o machine learning. Gracias a la mejora computacional de los procesadores actuales, estos sistemas ofrecen un equilibrio excelente entre precisión y velocidad de respuesta, razón por la cual son ideales para aplicaciones de procesamiento de imágenes. De esta forma, los sistemas puede ser entrenados para aprender a clasificar diferentes tipos de imágenes o para detectar y reconocer objetos buscados que aparecen en ellas.
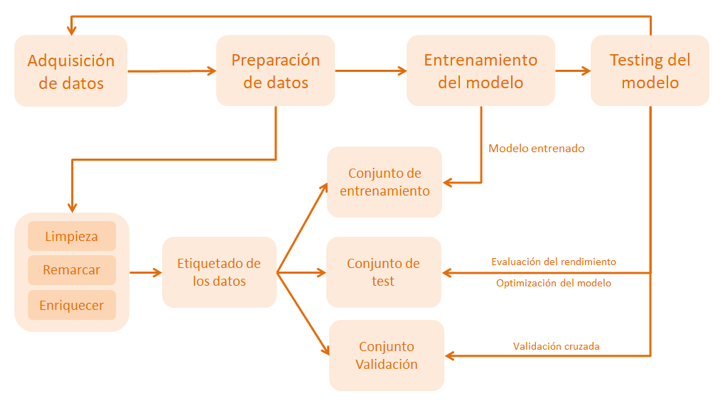
Ilustración 1 – Workflow típico del aprendizaje automático
Uno de los mayores problemas que presentan estos métodos es que para obtener buenos resultados la etapa de entrenamiento debe realizarse utilizando una gran cantidad de imágenes (cientos o incluso miles), que deben ser clasificadas y etiquetadas convenientemente para que el sistema de aprendizaje sea capaz de vincular de forma correcta las características de cada imagen con la etiqueta correspondiente. De esta forma, si se ha contado con una base de datos de imágenes los suficientemente amplia, variada y correctamente clasificada, será más fácil el desarrollo de un sistema de reconocimiento preciso.
Toda esta labor de recopilación de imágenes y etiquetado, que requiere de la selección de zonas de la imagen donde se encuentra el objeto a detectar/clasificar, además de ser una tarea tediosa, implica invertir mucho tiempo sólo en la preparación del conjunto de datos de entrenamiento.
Para facilitar este proceso, se ha pensado en aprovechar las ventajas que ofrecen los entornos virtuales, cada vez más realistas, para generar imágenes controladas programáticamente, en las que se tiene acceso inmediato a todos los objetos representados en ellas. Así, mediante scripts, se pueden examinar cada uno de los elementos de la escena que aparecen en cámara y etiquetar cada imagen de manera automática, y generando directamente los ficheros de datos necesarios para el entrenamiento con la estructura y formato adecuados.
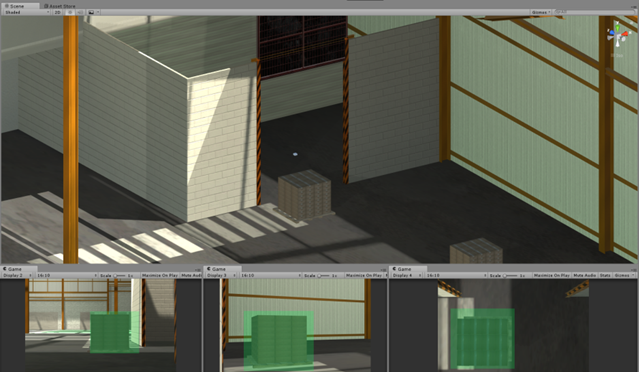
Imagen 2 – Ejemplo de etiquetado automático de objetos en la escena
Este enfoque permite la comprobación de los algoritmos en una infinidad de escenarios, de distinta naturaleza y complejidad, que de otra manera no sería factible. Así es posible la creación de sistemas con inteligencias más evolucionadas, que han aprendido de muchos más casos en una gran variedad de condiciones.
Hasta ahora, este enfoque ha sido aplicado por CTIC al entrenamiento de algoritmos de visión artificial para monitorización de entornos industriales, que han sido validados en un entorno controlado, comprobando las posibilidades que ofrece esta alternativa y permitiendo identificar algunas de sus limitaciones. Queda pendiente su aplicación a una mayor diversidad de casos, incluyendo escenarios más complejos, e incluso su utilización para entrenamiento o validación de otro tipo de inteligencias artificiales no necesariamente basadas en el uso de imágenes.
Carmen Campomanes.
Roberto González.
-Línea Tecnologías de Visión-
Proyecto financiado por la Unión Europea, a través del FEDER y por el Principado de Asturias, a través del Plan de Ciencia, Tecnología e Innovación 2018-2022.



