


Digitalización es el proceso por el cual transformamos cualquier tipo de información en un formato digital o procesable automáticamente. Este término se considera sinónimo de ‘transformación’ debido a la rápida adopción de las tecnologías en cualquier ámbito de nuestra sociedad.
Los servicios de datos e información, considerados como motor de la cuarta revolución industrial, o Industria 4.0, son estratégicos para grandes y pequeñas empresas, y están originando innovadores modelos de negocio que están agitando la economía mundial. Esta información digital no es más que la materia prima que alimenta el uso del IoT (internet de las cosas) y tecnologías como el big data, la analítica de datos o la inteligencia artificial, conceptos de moda que simplifican complejas arquitecturas, lenguajes o protocolos, y que están cambiando sectores tan tradicionales como la salud, la gestión de las ciudades, la construcción de viviendas, la agricultura o la industria primaria.
Uno de los mayores retos de la industria desde los comienzos de la digitalización es la interoperabilidad entre sistemas heterogéneos que usan sistemas de intercambio de información con formatos o esquemas distintos. Por ejemplo: sistemas legados obsoletos, empresas que se fusionan, selección de tecnologías propietarias, etc. Esta interoperabilidad es necesaria para poder ejecutar los procesos de tratamiento de los datos y obtener los resultados que motivan una transformación satisfactoria y eficiente.
Otra de las grandes barreras con las que se encuentran los sistemas es que la mayoría de los datos digitalizados se encuentran en formatos desestructurados —textos que pueden contener cifras, fechas u otros elementos sin una organización concreta— y su procesamiento no es trivial. Para solucionar estos dos grandes retos son necesarios los estándares.
Grafos de conocimiento
Una de las soluciones para la gestión de la información, teniendo en cuenta estas barreras, son los grafos de datos. Un grafo es una sencilla forma de representar relaciones entre entidades, que permite establecer los vínculos semánticos entre datos y metadatos, y realizar razonamientos a través de reglas que recorran los nodos según relaciones semánticas que se determinen.
El contenido de los grafos se puede enriquecer a través de anotaciones sobre los nodos y sus enlaces, permitiendo describir sus propiedades (p.e., procedencia, calidad, o ámbito de aplicación), incluso mediante descripciones semánticas que permitan un procesamiento automático “inteligente“. De esta forma, los grafos de datos se convierten en grafos de conocimiento.
Los grafos de conocimiento han sido popularizados por Google con su Knowledge Graph, utilizado para organizar la Web de una forma semántica y así ofrecer los resultados adecuados a los usuarios tras las búsquedas. Este grafo incluye conceptos como libros, series de TV, películas, álbumes de música, empresas, personas o lugares. Siguiendo este paradigma, un sistema automático podría navegar por el grafo para buscar información concreta por su concepto —p.e., se podría acceder a la información sobre la ciudad de Barcelona, independientemente de que existan otras entidades con la misma etiqueta que la denomina, ‘Barcelona’ como club de fútbol o ‘Barcelona’ como provincia—.
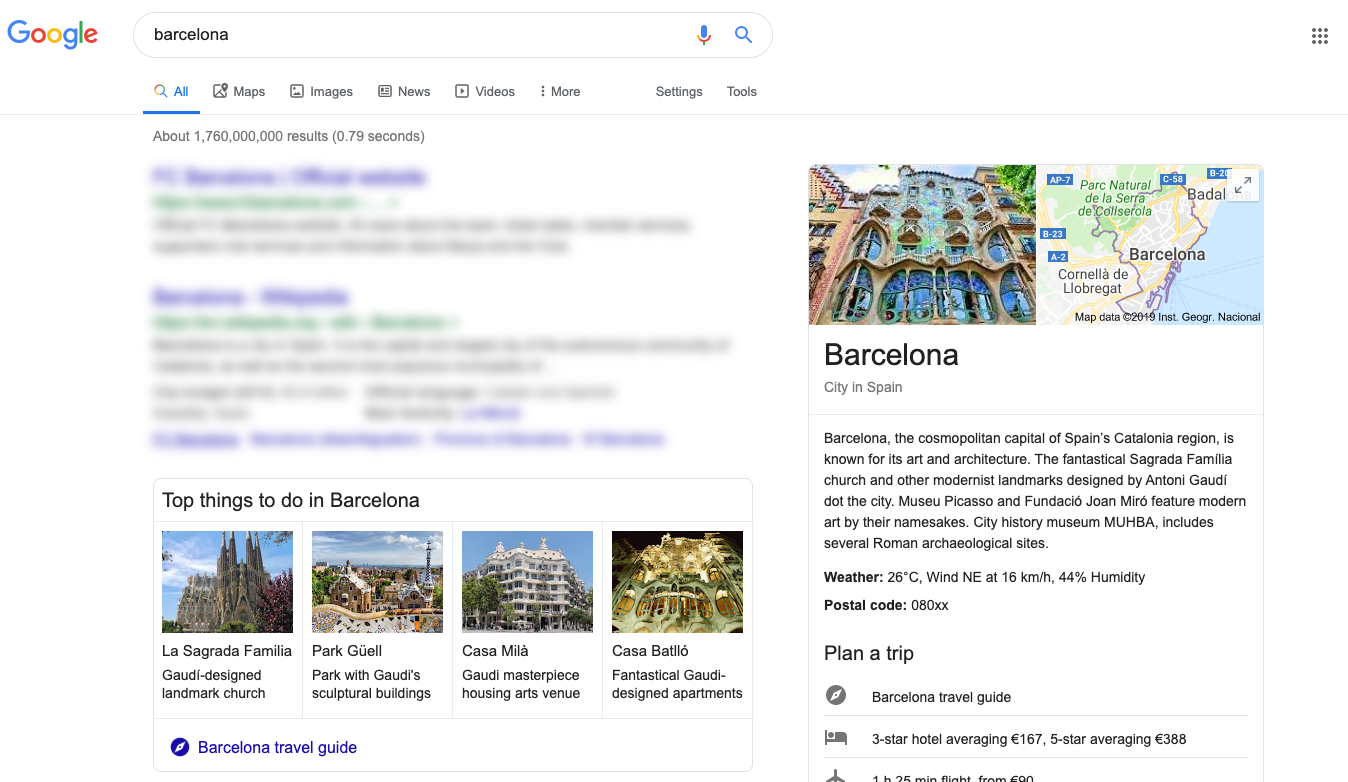
- Ejemplo de búsqueda y resultados enlazados con el concepto de ‘Barcelona’ -
La creciente tendencia de adopción de estos sistemas de organización de la información —y el conocimiento— se ve reflejada en la expansión de las bases de datos específicas para gestionar grafos, que han crecido exponencialmente en los últimos años, como puede observarse en la siguiente ilustración (representada en escala logarítmica).
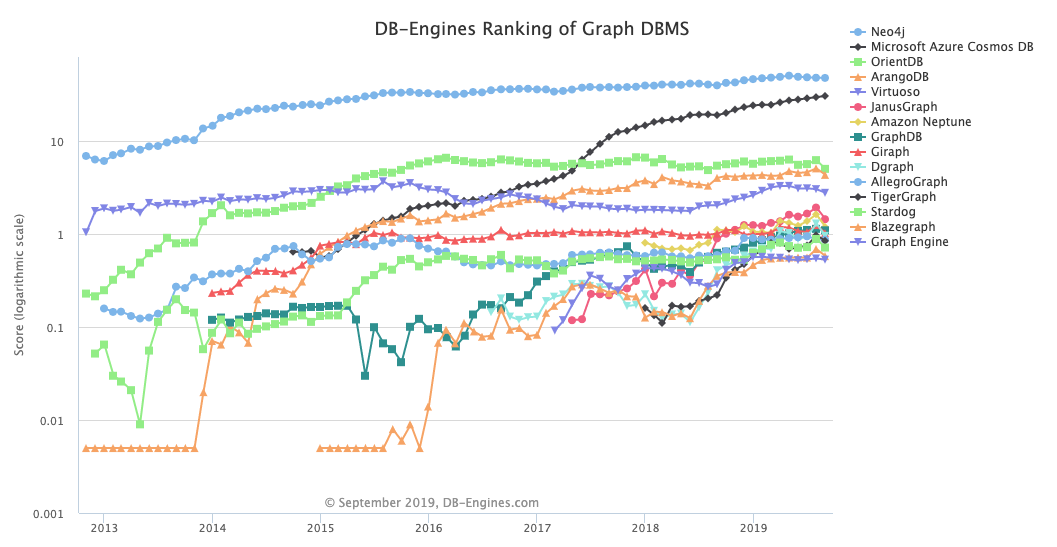
- Evolución del uso de bases de datos de grafos -
La Web Semántica como base
Allá por el 2003, el W3C comenzó a trabajar sobre los fundamentos de los grafos de datos, creando las primeras especificaciones para la Web Semántica, una serie de tecnologías encabezadas por el RDF (Resource Description Framework o infraestructura para la descripción de recursos) que permiten crear grafos de conocimiento universales gracias al uso de los protocolos y lenguajes de la Web. El RDF permite describir cualquier objeto (real o virtual) mediante tripletas del estilo <sujeto> – <predicado> – <objeto> (p.e., <Juan> <vive_en> <Barcelona>), ofreciendo un modelo simple e intuitivo para unir los extremos de las tripletas con otras descripciones, creando un grafo de conocimiento global.
Los objetos en RDF pueden ser descritos en múltiples idiomas y al identificarlos mediante identificadores Web (URI o Uniform Resource Identifier) del tipo <http://… /Juan> , el grafo se vuelve universal, permitiendo el acceso a los datos desde cualquier lugar y su combinación con otros grafos de conocimiento.
Estandarización de Grafos
Para dar solución a la evolución de estas tecnologías, el W3C acaba de lanzar el Grupo de Negocio de Estandarización de Grafos, un grupo de trabajo que pretende recopilar los casos de uso y requisitos desde todas las perspectivas y sectores, así como para guiar el trabajo de estandarización en esta materia.
Este grupo está buscando sinergias con otros equipos de estandarización, dentro y fuera del W3C, con el objetivo de conseguir la interoperabilidad de tecnologías una realidad. Un ejemplo de esto son las especificaciones de la Web de las Cosas (Web of Things o WoT, en inglés), de gran relevancia en la actualidad y basada en las tecnologías de grafos, que permiten —y permitirán— la generación de una ingente cantidad de información en forma de grafos de conocimiento, que pasará a formar parte del esta gran base de datos.
Aparte de la cantidad de datos estructurados y descritos para que las máquinas los comprendan, este trabajo de estandarización contribuirá a incrementar la eficiencia en la organización del conocimiento, ofreciendo mecanismos para evolucionar los algoritmos de razonamiento sobre el conocimiento y la gestión “inteligente” del gran grafo de conocimiento global que seguirá colaborando con la transformación nuestra sociedad.
Martín Álvarez-Espinar
-W3C Spain-
