


Una parte apreciable de los proyectos desarrollados en CTIC Centro Tecnológico tienen como requisito el procesamiento y gestión de grandes volúmenes de datos. Estos proyectos requieren del uso de tecnologías que adopten la escalabilidad como elemento principal de su diseño, y que son comúnmente englobadas dentro del campo de tecnologías Big Data. En este artículo se presentará un proyecto de estas características, desarrollado de manera conjunta entre las líneas de especialización de Web de las Cosas y de Inteligencia Artificial y Big Data.
El proyecto, denominado SmartLodging4Guest, tiene como objetivo el desarrollo de un sistema autónomo e inteligente que manipule las condiciones de un conjunto de apartamentos de un complejo hotelero, de manera que se optimice el confort global de los huéspedes, teniendo en cuenta sus preferencias y los datos históricos de estancias anteriores. La solución planteada integra técnicas de procesamiento de datos mediante tecnologías Big Data para la recolección, preprocesamiento y almacenamiento de datos, además de técnicas de análisis de datos para la optimización del confort.
Se identificó la necesidad de aplicar tecnologías Big Data por el volumen de datos a procesar. Cada apartamento a gestionar cuenta con aproximadamente 120 elementos sensores y actuadores que generan datos cada 1-2 segundos, produciendo alrededor de 22 millones de datos semanales. Aunque la propuesta fuera evaluada con datos procedentes en un único apartamento, se diseñó de manera que fuera aplicable a casos de uso con apartamentos adicionales del complejo hotelero.
A continuación, se presenta un esquema explicativo de la arquitectura planteada. Se describe la función de cada uno de los elementos que la componen, haciendo especial hincapié en aquellos que participan en la adquisición y almacenamiento de datos por su uso de tecnologías Big Data.
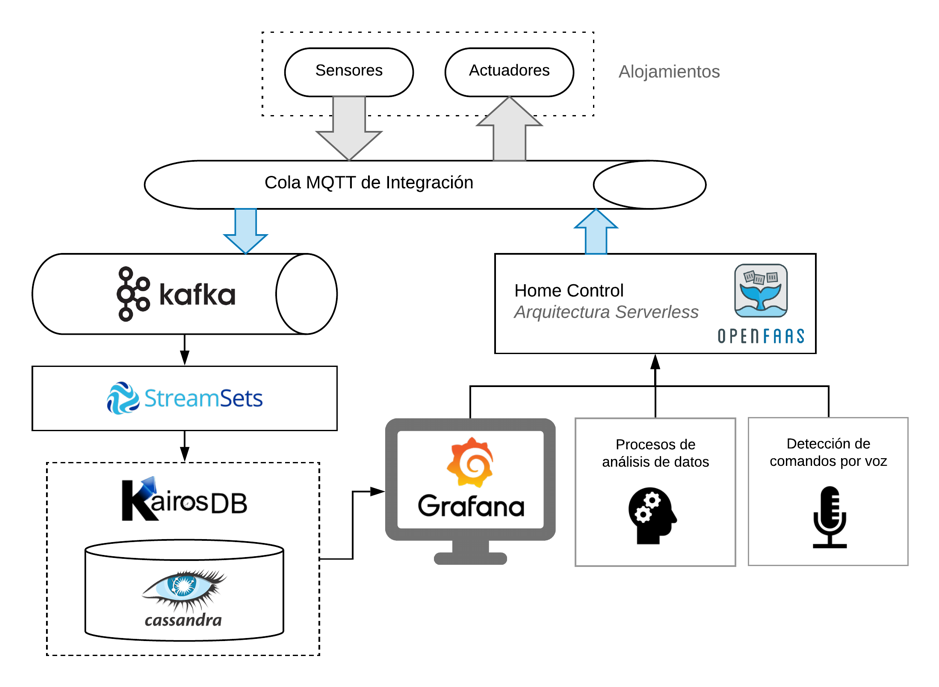
Los elementos sensores producen datos de manera regular en una cola MQTT dedicada en cada apartamento. Esto posibilita la lectura de estos valores por múltiples servicios de manera asíncrona y facilita la introducción de nuevos sensores en las instalaciones.
Los datos generados por los sensores son leídos de la cola MQTT e introducidos en Apache Kafka. Como sistema de mensajería estándar en entornos Big Data, ofrece garantías de tolerancia a fallos, persistencia y replicación de datos en casuísticas con alto volumen y frecuencia de datos. En el caso que nos ocupa, cumple las mismas funciones que la cola MQTT descrita previamente a una mayor escala, puesto que permite procesar volúmenes de datos mucho mayores.
Todos los datos de los apartamentos presentes en Apache Kafka deben ser leídos y almacenados de manera persistente en una base de datos. Para ello, es necesario realizar un preprocesamiento a los datos en bruto generados por los sensores. Esto permite detectar anomalías en los datos y uniformizar los datos a almacenar. Todo el proceso debe ser realizado en tiempo real sin introducir una latencia perceptible. Para realizar esta tarea se decidió utilizar la tecnología Streamsets DataCollector. Streamsets Data Collector es un motor de procesamiento de datos en tiempo real, utilizado para dirigir y procesar flujos de datos en sistemas complejos.
La siguiente imagen muestra el pipeline definido para el flujo de datos procedente de los sensores instalados en el apartamento. Está compuesto por un conjunto de transformaciones secuenciales que comienza con la lectura de datos de Kafka y finaliza con el envío de datos mediante peticiones HTTP. Las transformaciones intermedias formatean los datos en bruto y los normalizan para facilitar su almacenamiento posterior.
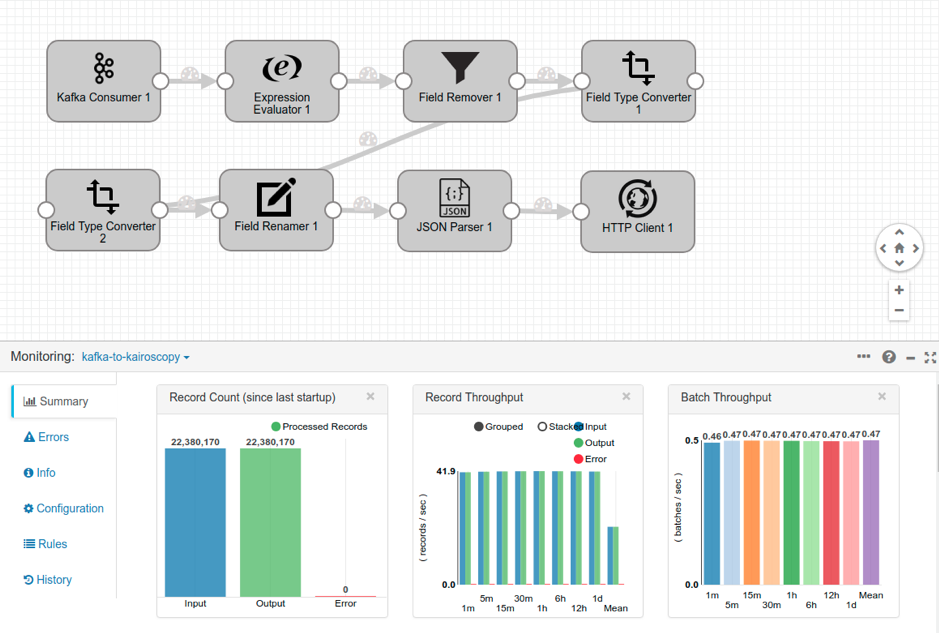
En esta imagen también se puede apreciar el volumen de datos procesado por el sistema y las capacidades de procesamiento por segundo. En aproximadamente una semana se producen 22 millones de datos, generados con una frecuencia de 42 por segundo.
Los datos de los sensores son almacenados de manera permanente en Apache Cassandra a través de la API HTTP proporcionada por KairosDB. KairosDB es una base de datos optimizada para el almacenamiento y gestión de series temporales, que utiliza Apache Cassandra como backend para el almacenamiento de datos.
Las bases de datos de series temporales almacenan valores escalares a lo largo del tiempo, añadiendo metadatos adicionales. Con respecto a las bases de datos relacionales en las que una fila de una tabla representaría un único escalar en un instante de tiempo, una base de datos de series temporales colapsa muchos valores escalares en una única fila que representa un intervalo de tiempo. La configuración básica de KairosDB maximiza el número de columnas por fila de manera que, para cada sensor, se almacenan 3 semanas de datos en una fila determinada de la base de datos.
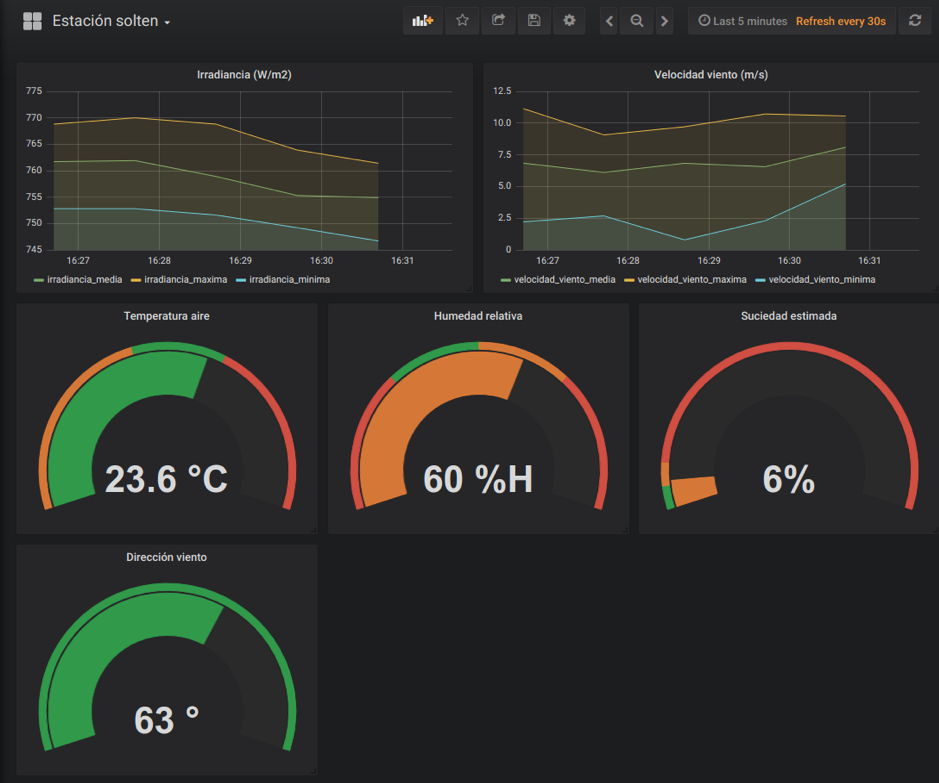
Finalmente, los datos almacenados en la base de datos pueden ser monitorizados en el dashboard de visualización, implementado en este caso mediante la herramienta Grafana. Estos datos son a su vez explotados por herramientas adicionales, como es el caso de los procesos de análisis de datos que optimizan el confort de los huéspedes de los apartamentos.
Un sistema de actuación adicional permite interactuar con una serie de elementos de control del apartamento de manera remota, como los interruptores, persianas, rejillas de ventilación y controles de iluminación. Este sistema de actuación monitoriza determinados mensajes de control publicados en la cola MQTT por otros componentes del sistema, como la aplicación de control por voz. La escritura de mensajes de control se realiza utilizando la tecnología serverless OpenFaas. De esta manera, se ha proporcionado un ejemplo real del proceso de integración de tecnologías Big Data en un proyecto que requiera el procesamiento y almacenamiento de grandes volúmenes de datos.
Iván Gallego
-Línea especialización de WoT-
